For my master’s thesis, I conducted a research project to find and test ways of improving player ranking systems in an online game. You can read “Abstracting Glicko-2 for Team Games” here.
Why this subject?
As a League of Legends player, I had personal investment in the subject of player rating systems. While a rating system should have decent predictive performance, I feel a player’s experience plays an important role in the overall quality of competitive play. An online game like League of Legends uses competitive play as a vital component to attracting new players and keeping current players invested. Players can quickly lose that investment if the rating system “feels” frustrating or unfair, even if the system rates their skill performance accurately most of the time.
Unfortunately, delivering a non-frustrating experience and an accurate predictive performance proves quite challenging for an online team game. These games typically rate player performance individually despite each match involving teams of multiple players. Microsoft’s TrueSkill tackles this problem directly, but research showed the system performs more poorly for games with less than eight players on each team. In some cases, Elo performed better! Thus, my research focused on improving player rating systems with this regard.
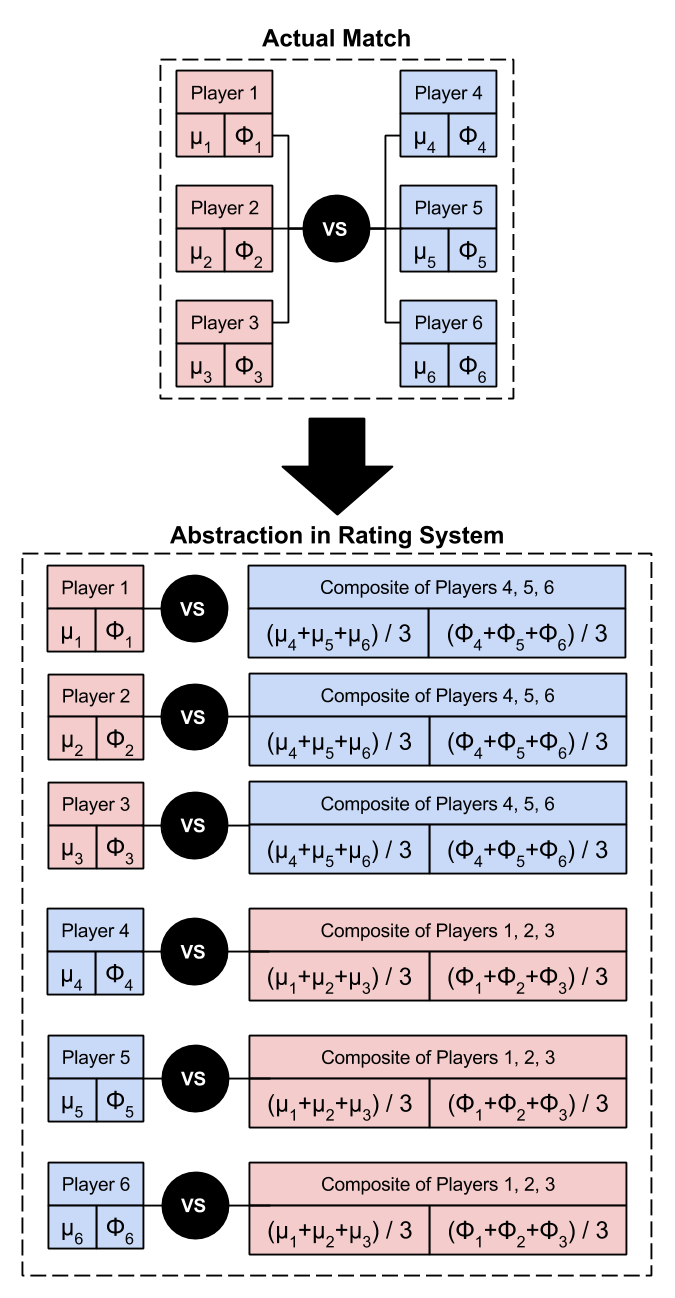
Composite Opponent abstracts this 3v3 team match as six 1v1 matches, one for each player against a “dummy” player that has the average rating of the opposing team.
Theory
In my thesis, I propose to “abstract” a team match as one or more one-versus-one matches. This method allows us to take advantage of the well established rating systems built for two-player games, like Glicko-2. Compatibility is also a perk — any game that uses a system based on Glicko-2 can utilize these abstraction methods.
For this project, I developed and tested three methods:
- Individual Update, which treats a team match as multiple one-on-one matches. For example, consider a player’s team winning a 3-versus-3 match. The system updates his rating three times as if he won three matches, one against each player on the opposing team. Tests showed it worked reasonably well, but unless the system makes certain adjustments, a player’s rating converges rather erratically due to each match being counted as multiple wins or losses.
- Composite Opponent, which creates a dummy player called a composite opponent that has the average rating of the opposing team. When updating a player’s rating, the system treats the match as a win or loss against that composite opponent. From the tests, this method had the best overall influence over the rating system’s behavior.
- Composite Team, which updates a player according to the average of their team’s rating. Tests showed that this method is not viable in its current state and requires further iteration.
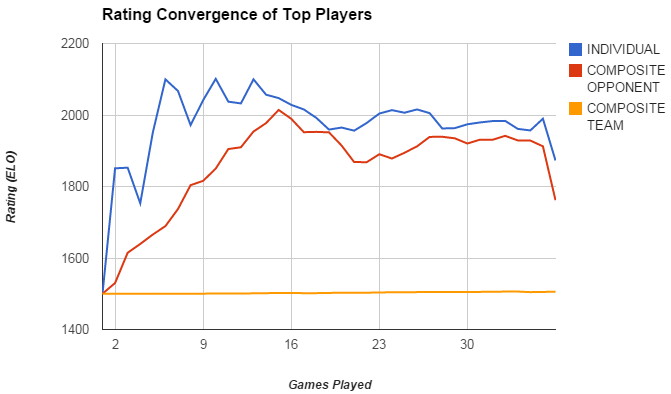
The top player’s rating for the Individual and Composite Opponent methods converge towards his true skill at closely the same rate. However, the Individual method makes his rating change erratically for his early games.
Practice
Testing the abstraction methods required developing a testing suite, which took up the bulk of the project’s time. I created a Java program designed to simulate the matchmaking queue of an online competitive team game and run automated matches. For the match data, I used SoccerBots and SBTournament, applications created for testing and running 5-versus-5 soccer games played by automated robots.
I gathered data from three runs for each abstraction method, each run consisting of 100 games and a pool of 25 robot players. I analyzed the data based on predictive performance, how the top player’s rating converges towards their true skill, and how win rates correlates with each player’s ranking.
Conclusion
Data from the testing runs showed that the Composite Opponent method had the most favorable influence on the rating system. While the system was slightly better at predicting match outcomes with Individual Update, Composite Opponent fared better overall. I believe the method could be further developed to create a more elaborate composite opponent, such as weighting the composite’s rating based on player proximity or points of interaction.
Though frustrating at times, I enjoyed working on this project and plan to update this article with a Github link to the testing software I developed.